KVMesh: A C++ Distributed Key-Value Store
Welcome to my journey into the world of distributed systems! In this blog post, I’ll be sharing my experience building KVMesh, a distributed key-value store implemented in C++. I’ll dive into the design decisions, implementation details, challenges faced, and lessons learned along the way. My goal is to create a system that is not only performant and scalable but also resilient to failures.
Table of Contents
- KVMesh: A C++ Distributed Key-Value Store
- Project Goals
- System Design
- Implementation Details
- Performance Optimization and Evaluation
- Challenges
- Testing
- Future Work
- References
Project Goals
The primary goals of KVMesh are to:
- Durability and Consistency: Provide reliable storage across multiple nodes, ensuring data persistence and consistency even in the face of failures.
- Fault Tolerance: Gracefully handle node failures, network partitions, and other potential disruptions.
- Scalability: Scale horizontally with minimal overhead, allowing the system to grow seamlessly as demand increases.
- High Concurrency: Efficiently handle a large number of concurrent read and write requests.
- Flexibility: Support multiple eviction policies, starting with Least Recently Used (LRU) with optional Time-to-Live (TTL).
System Design
Peer-to-Peer Model
KVMesh employs a peer-to-peer (P2P) decentralized model, where each node in the cluster can act as both a client and a server. This design choice was driven by the desire for simplicity, fault tolerance, and scalability. Unlike a primary-backup model, a P2P architecture eliminates the single point of failure and bottleneck associated with a central primary node. In KVMesh, any node can receive and serve client requests, distributing the load evenly across the cluster.
The core of this distributed system lies in consistent hashing, a technique that allows us to distribute data evenly across multiple nodes while minimizing data movement when nodes are added or removed. More on this later!
Inter-Node Communication with gRPC and Protobuf
For efficient inter-node communication, KVMesh leverages the power of gRPC and Protocol Buffers (Protobuf). gRPC, a high-performance, open-source universal RPC framework, provides a robust foundation for building distributed systems. Its use of HTTP/2 enables features like multiplexing and header compression, which contribute to reduced latency and improved throughput.
Protobuf, on the other hand, serves as the interface definition language (IDL) and serialization mechanism. By defining our data structures and service methods in .proto files, we can generate efficient and type-safe code for serialization and deserialization. This ensures that data exchanged between nodes is compact, fast to process, and less prone to errors.
Request Handling
Let’s take a look at how KVMesh handles different types of client requests:
Put Request
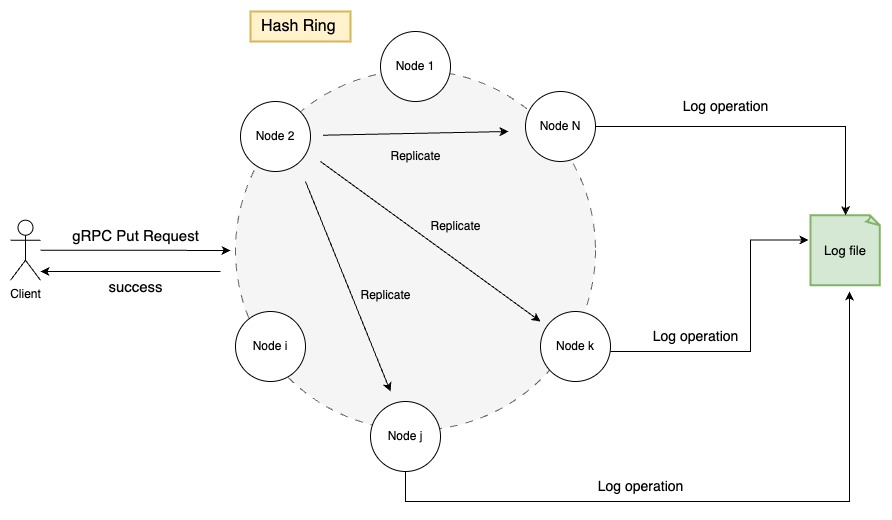
- Client Request: A client initiates a request to insert a key-value pair.
- Consistent Hashing: The receiving node (any node in the cluster) uses consistent hashing to determine the nodes responsible for storing the key.
- Local or Forward: If the current node is responsible, it writes the data to its local LRU cache. Otherwise, it forwards the request to one of the responsible nodes.
- Write-Ahead Logging: Before acknowledging the write, the node logs the operation to a Write-Ahead Log (WAL) for durability.
- Replication: The request is asynchronously replicated to other responsible nodes to ensure redundancy.
- Acknowledgement: The client receives a success response once the data is written to the WAL and replicated.
Get Request
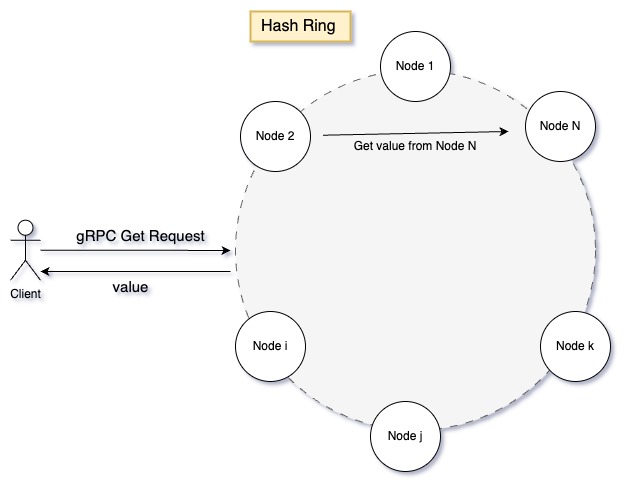
- Client Request: A client requests the value associated with a specific key.
- Consistent Hashing: The receiving node uses consistent hashing to identify the nodes that might hold the key.
- Local or Forward: If the current node is responsible, it retrieves the value from its local LRU cache. Otherwise, it forwards the request to a responsible node.
- Response: The client receives the value associated with the key.
Remove Request
The remove request follows a similar process to the put request. It ensures that a key-value pair is deleted from all responsible nodes.
Implementation Details
Consistent Hashing: The Core of Data Distribution
Consistent hashing is the backbone of KVMesh’s data distribution strategy. It allows us to map keys and nodes to a virtual ring, called the “hash ring.”
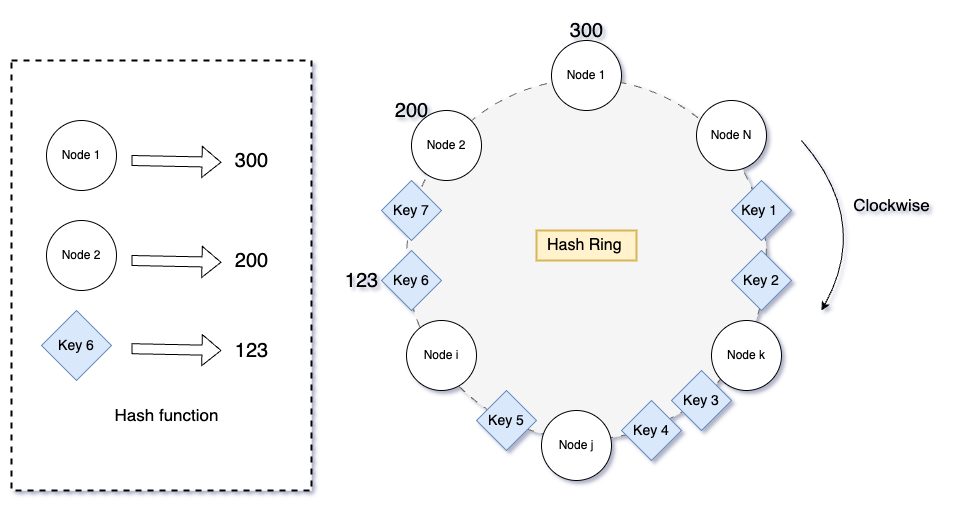
Each node and key is hashed using a hash function, and their positions on the ring are determined by their hash values.
| |
To find the nodes responsible for a key, we move clockwise along the ring from the key’s position until we encounter the desired number of distinct nodes.
| |
Note: I’m planning to optimize getNodes by using a std::set instead of a std::vector to avoid duplicate node entries, improving efficiency.
Virtual Nodes for Even Distribution
One challenge with consistent hashing is the potential for uneven data distribution, especially when the number of nodes is small. To address this, KVMesh employs virtual nodes.
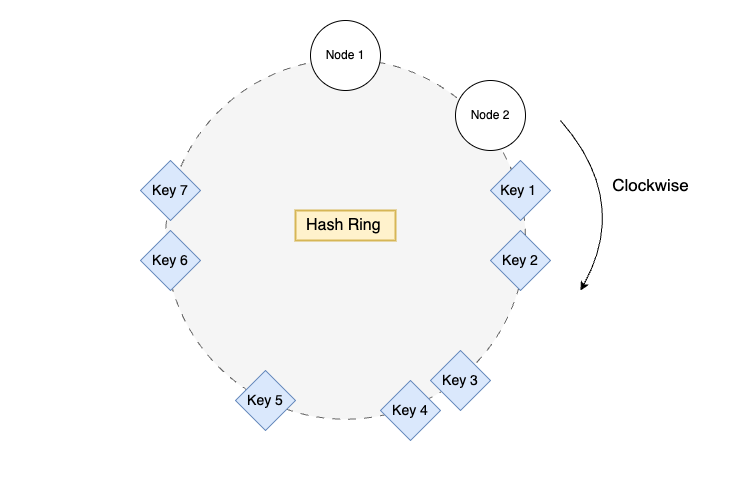
In a worst-case scenario, keys might be clustered around a single node, leading to load imbalance. In the diagram above, all keys are assigned to Node 1, and no keys are assigned to Node 2. Virtual nodes help mitigate this by creating multiple virtual instances of each physical node on the ring.
| |
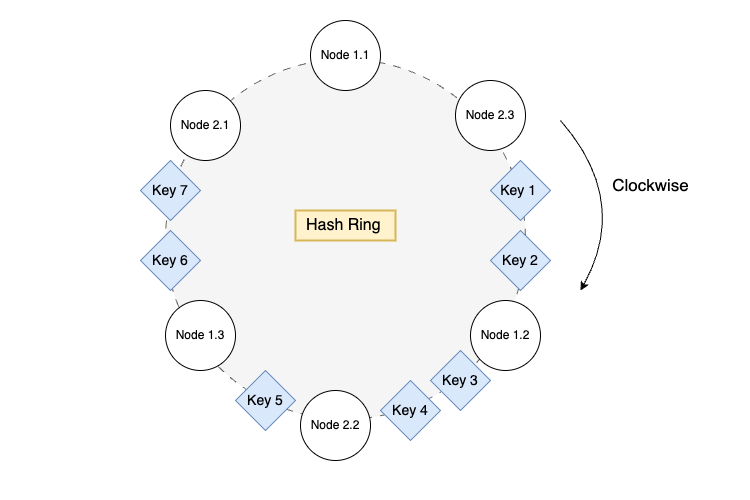
By appending a unique identifier to each node ID and hashing it multiple times, we create virtual nodes (e.g., Node 1.1, Node 1.2, Node 2.1) that are more evenly distributed around the ring, leading to better load balancing.
LRU Cache with TTL
Each node in KVMesh maintains an in-memory LRU (Least Recently Used) cache for fast data access. The LRU cache is implemented using a combination of a std::unordered_map and a std::list to maintain the order of items based on their usage. std::unordered_map maps the key to the iterator of the cache item in the list, depicted in the diagram below.
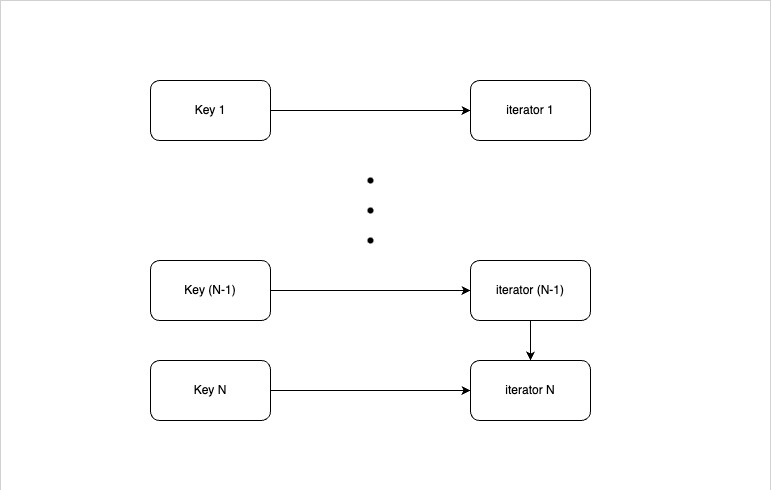
| |
Each CacheItem stores the key, value, and an optional expiry time for TTL functionality.
Put Operation
| |
When a new item is added, it’s placed at the front of the list. If the key already exists, its value is updated, and it’s moved to the front. If the cache exceeds its capacity, the least recently used item (at the back of the list) is evicted.
Get Operation
| |
When an item is accessed, it’s moved to the front of the list, indicating its recent use.
Thread Safety
Both put and get operations use a std::lock_guard to ensure thread-safe access to the cache, preventing race conditions in a multi-threaded environment.
(If you wanna practice how to implement LRU cache, go do leetcode problem.)
Write-Ahead Logging (WAL) for Durability and Consistency
To ensure data durability and consistency, KVMesh implements Write-Ahead Logging (WAL). Before any modification is made to the in-memory cache, the operation (Put or Remove) is first serialized using Protobuf and written to the WAL file.
Log Entry Format
Each log entry contains:
- Operation type (Put/Remove)
- Timestamp
- Key
- Value (for Put operations)
- Checksum (for data integrity verification)
Checksum for Data Integrity
KVMesh uses the CRC32 algorithm from the Boost library to calculate a checksum for each log entry.
| |
This checksum is stored along with the log entry and is used during recovery to detect and prevent data corruption.
Recovery Process
In the event of a system failure or restart, the recovery manager reads the WAL file sequentially, validates each entry’s checksum, and replays the operations in chronological order to rebuild the in-memory state of the cache.
Current Limitations and Future Improvements
Currently, the WAL file is shared among all nodes, which creates a single point of failure. I’m exploring the following improvements:
- Per-Node WAL Files: Each node will maintain its own WAL file, eliminating the single point of failure and potentially improving write performance.
- Log Compaction: Periodically compact the WAL file to prevent unbounded growth and reduce recovery time.
- Snapshots: Create periodic snapshots of the cache state to speed up recovery.
Coordinating log compaction and snapshots in a distributed environment with per-node WAL files presents interesting challenges. I’m considering using a consensus algorithm or a distributed transaction mechanism to ensure consistency across nodes during these operations.
Write Queue: Asynchronous Logging
To minimize the performance impact of writing to the WAL, KVMesh employs a thread-safe Write Queue. Log entries are buffered in this queue and written to disk in batches, reducing the frequency of disk I/O operations.
| |
The flush_thread_ periodically checks the queue and writes a batch of log entries to disk when either the queue size exceeds a predefined batch_size_ or a certain flush_interval_ has elapsed.
Condition Variable for Efficient Waiting
The flush_thread_ uses a std::condition_variable (cv_) along with a std::mutex (queue_mutex_) to efficiently wait for new entries or the flush interval to expire. The cv_.wait_for method allows the thread to sleep until either the specified duration elapses or the provided predicate becomes true.
The predicate !running_ || queue_.size() >= batch_size_ ensures that the thread wakes up and processes the queue when:
- The system is shutting down (
!running_). - The queue size reaches the
batch_size_.
Performance Observations
Interestingly, in my initial tests, the Write Queue didn’t provide a significant performance improvement. I suspect this is because I’m currently writing to an SSD and dealing with relatively small string values. The overhead of batching might be outweighing the benefits in this scenario. However, I anticipate that the Write Queue will become more beneficial when dealing with larger values/objects or slower storage devices (e.g., HDDs).
Node Class: Orchestrating the Components
The Node class is the central component of each KVMesh node. It integrates the various modules and manages the gRPC service for handling client requests.
Channel Pool for Efficient gRPC Connections
The Node class maintains a pool of gRPC channels for communication with other nodes. This avoids the overhead of creating a new connection for each request.
| |
The getOrCreateChannel method provides a thread-safe way to retrieve an existing channel or create a new one if it doesn’t exist in the pool.
Cleanup Thread for TTL Management
Each node runs a dedicated cleanup thread (cleanup_thread_) that periodically removes expired items from the LRU cache.
| |
The cleanup method iterates through the cache list and removes any items whose expiry time is in the past. It uses a std::lock_guard to ensure thread-safe access to the cache during cleanup.
Potential Enhancements
- Batch Expiry: Process expired items in batches to reduce lock contention.
- Metrics: Collect metrics on cleanup operations to monitor performance and identify potential bottlenecks.
- Distributed TTL Coordination: Explore mechanisms for coordinating TTL expiration across nodes in a distributed manner.
Performance Optimization and Evaluation
During the development of KVMesh, I encountered several performance bottlenecks and implemented optimizations to address them.
Channel Pooling
Initially, I was creating a new gRPC channel for each inter-node request. Profiling revealed that this was a significant bottleneck. By implementing a channel pool, I observed an 8-9x improvement in read and write throughput.
Write Queue
As mentioned earlier, the Write Queue didn’t yield significant gains in my initial tests with SSDs and small values. However, I expect it to be more beneficial in scenarios with slower storage or larger data sizes.
Load Test Results
I conducted load tests using a Python client to simulate concurrent read and write operations. Here are some results from a 5-node cluster running on a Mac M3 Max with 36GB RAM:
| Metric | Scenario 1: Client interacts with a single node | Scenario 2: Client forwards requests to one of 5 random nodes |
|---|---|---|
| Write throughput (ops/sec) | 3116.01 | 2952.56 |
| Read throughput (ops/sec) | 7384.24 | 6731.89 |
| Average write time (ms/op) | 0.32 | 0.34 |
| Average read time (ms/op) | 0.14 | 0.15 |
Interestingly, the performance was slightly worse when the client interacted with random nodes. I attribute this to factors like connection management overhead, channel pool efficiency, and TCP connection reuse. Further investigation is needed to pinpoint the exact cause.
Challenges
The most significant challenges I faced were related to writing correct and efficient thread-safe code. I encountered my first deadlock during testing, which I eventually resolved through careful tracing and debugging.
Testing
I employed a combination of unit tests and load tests using a Python client. The unit tests focused on individual components like the LRU cache, consistent hash, and WAL. The load tests evaluated the overall system performance under concurrent read and write operations.
The Python client uses the grpc library to communicate with the KVMesh nodes. It provides methods for put, get, and remove operations.
Future Work
Here are some areas I’m planning to explore in the future:
- Per-Node WAL Files: Implement per-node WAL files to eliminate the single point of failure and improve write performance.
- Log Compaction and Snapshots: Develop mechanisms for efficient log compaction and snapshotting in a distributed environment.
- Improved Load Balancing: Investigate more sophisticated load balancing algorithms to handle skewed data distributions.
- Caching Enhancements: Explore more advanced caching strategies, such as adaptive caching and prefetching.
- Monitoring and Metrics: Implement comprehensive monitoring and metrics collection to gain insights into system performance and identify bottlenecks.
- Security: Add security features like authentication and encryption to protect data in transit and at rest.
References
I hope this blog post has provided valuable insights into the design and implementation of a distributed key-value store. Stay tuned for more updates! Comments, suggestions, feedbacks and questions are welcome!